Output schema definition language (OSDL)
Overview
This page contains an overview of the output schema definition language (OSDL), a custom language that can be used to define custom schemas for the extracted data.
So, what is a custom output schema? Whenever you perform an extraction, DocHeart outputs the extracted data in the form of a JSON object that follows a certain predefined schema (or structure), as specified in the documentation of the extraction results queries. However, this predefined schema might be far away from the data models you use internally in your application. To make your life as easy as possible and decrease the time and effort required to integrate your application with DocHeart, we allow you to define a custom schema in which the extracted data will be outputted. The language in which the custom schema is defined is OSDL, which supports both JSON and XML formats. We will provide you a guide on how to use OSDL in the following sections.
OSDL
As specified above, OSDL (output schema definition language) is the language used to specify a custom schema in which DocHeart should output the extracted data. OSDL is designed for ease of use, as it is a basic extension of JSON or XML. An output schema defined in OSDL is essentially a JSON object or an XML structure in which the values are expressions that reference fields and tables that will be extracted. Whenever the output schema is evaluated, the expressions in the schema are substituted with the referenced extracted fields and tables, which results in an extracted data object that has a custom format. As an example is worth 10000 DocHeart tokens :), let’s have a look at a concrete situation.
We will consider the following document:

And the following extraction configuration:

We will define the following example JSON and XML output schema, which references 3 fields in our configuration:
-
{ "Invoice Data": { "Name of contact person": "@FieldValue[Data.Name]", "Phone number": "@FieldValue[Data.Phone]", "Contact email address": "@FieldValue[Data.Email]" }, "Invoice Data Joined": "$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')" } -
<Invoice_Data> <Name_of_contact_person>@FieldValue[Data.Name]</Name_of_contact_person> <Phone_number>@FieldValue[Data.Phone]</Phone_number> <Contact_email_address>@FieldValue[Data.Email]</Contact_email_address> </Invoice_Data> <Invoice_Data_Joined>$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')</Invoice_Data_Joined>
Given the output schema defined above, the extracted data for the example document will be outputted in the following format, either in JSON or XML depending on the specified schema:
-
{ "Invoice Data": { "Name of contact person": "Emma", "Phone number": "(123) 451-7897", "Contact email address": "emma@fieldlab.nl" }, "Invoice Data Joined": "Emma|emma@fieldlab.nl|(123) 451-7897" } -
<Invoice_Data> <Name_of_contact_person>Emma</Name_of_contact_person> <Phone_number>(123) 451-7897</Phone_number> <Contact_email_address>emma@fieldlab.nl</Contact_email_address> </Invoice_Data> <Invoice_Data_Joined>Emma|emma@fieldlab.nl|(123) 451-7897</Invoice_Data_Joined>
As you can see, all expressions containing the keyword @FieldValue[<Group name>.<Field name>] have been substituted with the values extracted for the specified field. Such an expression, which directly references a value to be included in the final output is called a referencer.
Another aspect to notice is that the last entry in the outputted result, called Invoice Data Joined, contains multiple extracted values joined together by |. This results from applying the join operator on multiple referencers. In OSDL, an operator is similar to a function or method. It takes one or multiple referencers as arguments, it performs some computation dependent on the nature of the operator, and then it outputs the result.
Any OSDL schema is an arbitrary JSON object or XML structure, whose values consist of expressions made up of a combination of referencers and operators. We will have a deep look at both in the next two sections.
Referencers
A referencer is a special type of keyword in OSDL used to reference a piece of extracted data to be included in the final output. Referencers always start with @, and have a name and one or multiple arguments. A generic referencer has the following structure:
@<Referencer name>[argument 1][argument 2]...[argument k]
Currently, DocHeart supports 4 types of referencers: @FieldValue[<Group name>.<Field name>], @FieldValueList[<Group name>.<Field name>], @Table[<Group name>] and @Fixed[<Fixed Value>]. We will explain each one if them in detail.
@FieldValue[<Group name>.<Field name>]
The field value referencer is the most basic type of referencers. It is used to reference fields that expect a single extracted value (i.e. Allow multiple values is unchecked). Field value referencers take a single argument, of the form <Group name>.<Field name>, specifying the group name and field name of the value being referenced. If either the group name and the field name contain spaces, they should be written in-between apostrophes, as in the example below:
@FieldValue['Contact data'.'Contact email']
@FieldValueList[<Group name>.<Field name>]([<index>])
The field value list referencer works in a similar way to the field value referencer. The core difference is that rather than referencing a single value, it references a list of extracted values. This means that the field value list referencers will be used in combination with fields that expect a list of values (i.e. Allow multiple values is checked).
Let’s have a look at an example. We will augment the extraction configuration defined in the previous section to extract all numerical values found in the document:

We will now modify our schema to reference the extracted list of numerical values:
-
{ "Invoice Data": { "Name of contact person": "@FieldValue[Data.Name]", "Phone number": "@FieldValue[Data.Phone]", "Contact email address": "@FieldValue[Data.Email]" }, "Invoice Data Joined": "$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')", "All numerical values in Invoice": "@FieldValueList[Data.'Numerical values']" } -
<Invoice_Data> <Name_of_contact_person>@FieldValue[Data.Name]</Name_of_contact_person> <Phone_number>@FieldValue[Data.Phone]</Phone_number> <Contact_email_address>@FieldValue[Data.Email]</Contact_email_address> </Invoice_Data> <Invoice_Data_Joined>$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')</Invoice_Data_Joined> <All_numerical_values_in_Invoice> <Numbers>@FieldValueList[Data.'Numerical values']</Numbers> </All_numerical_values_in_Invoice>
Let’s have a look at the output:
-
{ "Invoice Data": { "Contact email address": "emma@fieldlab.nl", "Name of contact person": "Emma", "Phone number": "(123) 451-7897" }, "Invoice Data Joined": "Emma|emma@fieldlab.nl|(123) 451-7897", "All numerical values in Invoice": ["431", "326", "16", "2", "2023", "123", "456", "7892", "215", "321", "851", "521", "200", "375" "50", "4", "25", "56", "551", "56", "11", "21", "17", "100", "10", "30", "13", "25", "54", "5"] } -
<Invoice_Data> <Contact_email_address>emma@fieldlab.nl</Contact_email_address> <Name_of_contact_person>Emma</Name_of_contact_person> <Phone_number>(123) 451-7897</Phone_number> </Invoice_Data> <Invoice_Data_Joined>Emma|emma@fieldlab.nl|(123) 451-7897</Invoice_Data_Joined> <All_numerical_values_in_Invoice> <Numbers>431</Numbers> <Numbers>326</Numbers> <Numbers>16</Numbers> <Numbers>2</Numbers> <Numbers>2023</Numbers> <Numbers>215</Numbers> <Numbers>321</Numbers> <Numbers>851</Numbers> <Numbers>521</Numbers> <Numbers>200</Numbers> <Numbers>00</Numbers> <Numbers>375</Numbers> <Numbers>00</Numbers> <Numbers>50</Numbers> <Numbers>00</Numbers> <Numbers>4</Numbers> <Numbers>25</Numbers> <Numbers>26</Numbers> <Numbers>56</Numbers> <Numbers>551</Numbers> <Numbers>56</Numbers> <Numbers>11</Numbers> <Numbers>21</Numbers> <Numbers>17</Numbers> <Numbers>100</Numbers> <Numbers>10</Numbers> <Numbers>30</Numbers> <Numbers>13</Numbers> <Numbers>25</Numbers> <Numbers>54</Numbers> <Numbers>5</Numbers> </All_numerical_values_in_Invoice>
Wow! There are quite a few numerical values in our invoice. What if we are interested in just a sample? Luckily OSDL has you covered, since the field value list referencer supports an optional index argument, that allows you to select only a subset of the extracted values. Indexing can be performed in 2 different ways:
- by providing a list of individual entries, e.g. @FieldValueList[Data.’Numerical values’][0, 3, 5, 7]
- by providing a range, e.g. @FieldValueList[Data.’Numerical values’][1:4]. In the provided range, the start entry is included, while the last entry is excluded (similar to how ranges work in Python).
Let us try both:
-
{ "Invoice Data": { "Name of contact person": "@FieldValue[Data.Name]", "Phone number": "@FieldValue[Data.Phone]", "Contact email address": "@FieldValue[Data.Email]" }, "Invoice Data Joined": "$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')", "All numerical values in Invoice": "@FieldValueList[Data.'Numerical values']", "Indexing": { "by entries": "@FieldValueList[Data.'Numerical values'][0, 3, 5, 7]", "by range": "@FieldValueList[Data.'Numerical values'][1:4]" } } -
<Invoice_Data> <Name_of_contact_person>@FieldValue[Data.Name]</Name_of_contact_person> <Phone_number>@FieldValue[Data.Phone]</Phone_number> <Contact_email_address>@FieldValue[Data.Email]</Contact_email_address> </Invoice_Data> <Invoice_Data_Joined>$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')</Invoice_Data_Joined> <All_numerical_values_in_Invoice> <Numbers>@FieldValueList[Data.'Numerical values']</Numbers> </All_numerical_values_in_Invoice> <Indexing> <by_entries>@FieldValueList[Data.'Numerical values'][0, 3, 5, 7]</by_entries> <by_range>@FieldValueList[Data.'Numerical values'][1:4]</by_range> </Indexing>
Applying the new schema will yield the following results:
-
{ "Invoice Data": { "Contact email address": "emma@fieldlab.nl", "Name of contact person": "Emma", "Phone number": "(123) 451-7897" }, "Invoice Data Joined": "Emma|emma@fieldlab.nl|(123) 451-7897", "All numerical values in Invoice": ["431", "326", "16", "2", "2023", "123", "456", "7892", "215", "321", "851", "521", "200", "375" "50", "4", "25", "56", "551", "56", "11", "21", "17", "100", "10", "30", "13", "25", "54", "5"], "Indexing": { "by entries": ["431", "2", "123", "7892"], "by range": ["326", "16", "2"] } } -
<Invoice_Data> <Contact_email_address>emma@fieldlab.nl</Contact_email_address> <Name_of_contact_person>Emma</Name_of_contact_person> <Phone_number>(123) 451-7897</Phone_number> </Invoice_Data> <Invoice_Data_Joined>Emma|emma@fieldlab.nl|(123) 451-7897</Invoice_Data_Joined> <All_numerical_values_in_Invoice> <Numbers>431</Numbers> <Numbers>326</Numbers> <Numbers>16</Numbers> <Numbers>2</Numbers> <Numbers>2023</Numbers> <Numbers>215</Numbers> <Numbers>321</Numbers> <Numbers>851</Numbers> <Numbers>521</Numbers> <Numbers>200</Numbers> <Numbers>00</Numbers> <Numbers>375</Numbers> <Numbers>00</Numbers> <Numbers>50</Numbers> <Numbers>00</Numbers> <Numbers>4</Numbers> <Numbers>25</Numbers> <Numbers>26</Numbers> <Numbers>56</Numbers> <Numbers>551</Numbers> <Numbers>56</Numbers> <Numbers>11</Numbers> <Numbers>21</Numbers> <Numbers>17</Numbers> <Numbers>100</Numbers> <Numbers>10</Numbers> <Numbers>30</Numbers> <Numbers>13</Numbers> <Numbers>25</Numbers> <Numbers>54</Numbers> <Numbers>5</Numbers> </All_numerical_values_in_Invoice> <Indexing> <by_entries>431</by_entries> <by_entries>2</by_entries> <by_entries>123</by_entries> <by_entries>7892</by_entries> <by_range>326</by_range> <by_range>16</by_range> <by_range>2</by_range> </Indexing>
@Table[<Group name>]([<table index>])([<columns>])([<rows index>])
As the name suggests, the table referencer is used to reference tables. It is a bit more complex than the other 2 referencers, as it can take up to 3 optional arguments:
- table index - allows you to specify which table to reference (as the table extractor extract all tables that match the provided header schema). If left empty, all tables are being referenced. It follows the same syntax as the field value list index.
- columns - used to specify the columns to be referenced. If left empty, all columns will be referenced.
- rows index - allows you to specify which rows to reference. If left empty, all rows will be referenced. It follows the same syntax as the field value list index.
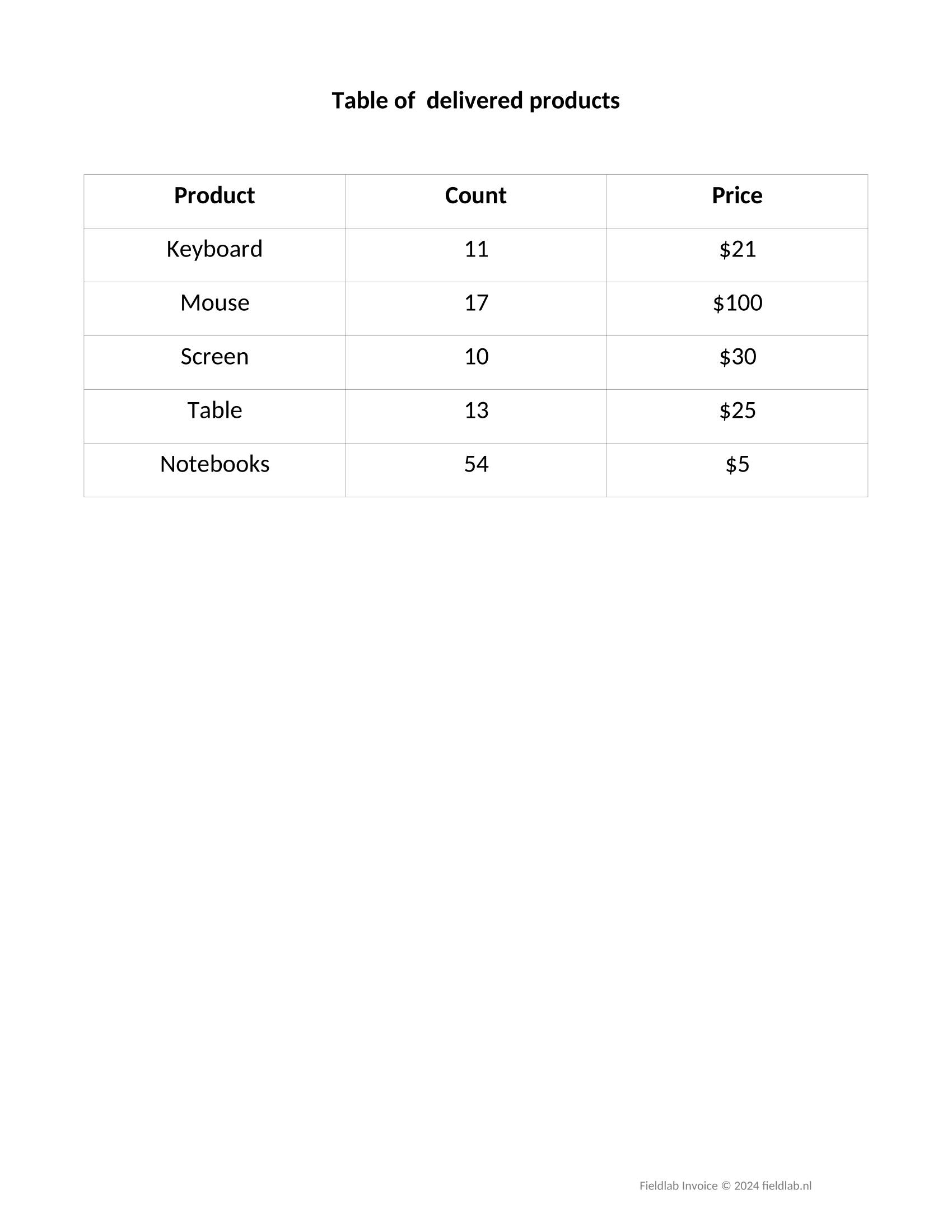
All of these arguments might seem confusing, but don’t worry. We will illustrate the use of each in the example below. To illustrate table indexing, we will augment the input document with another page containing a different table with a similar structure:
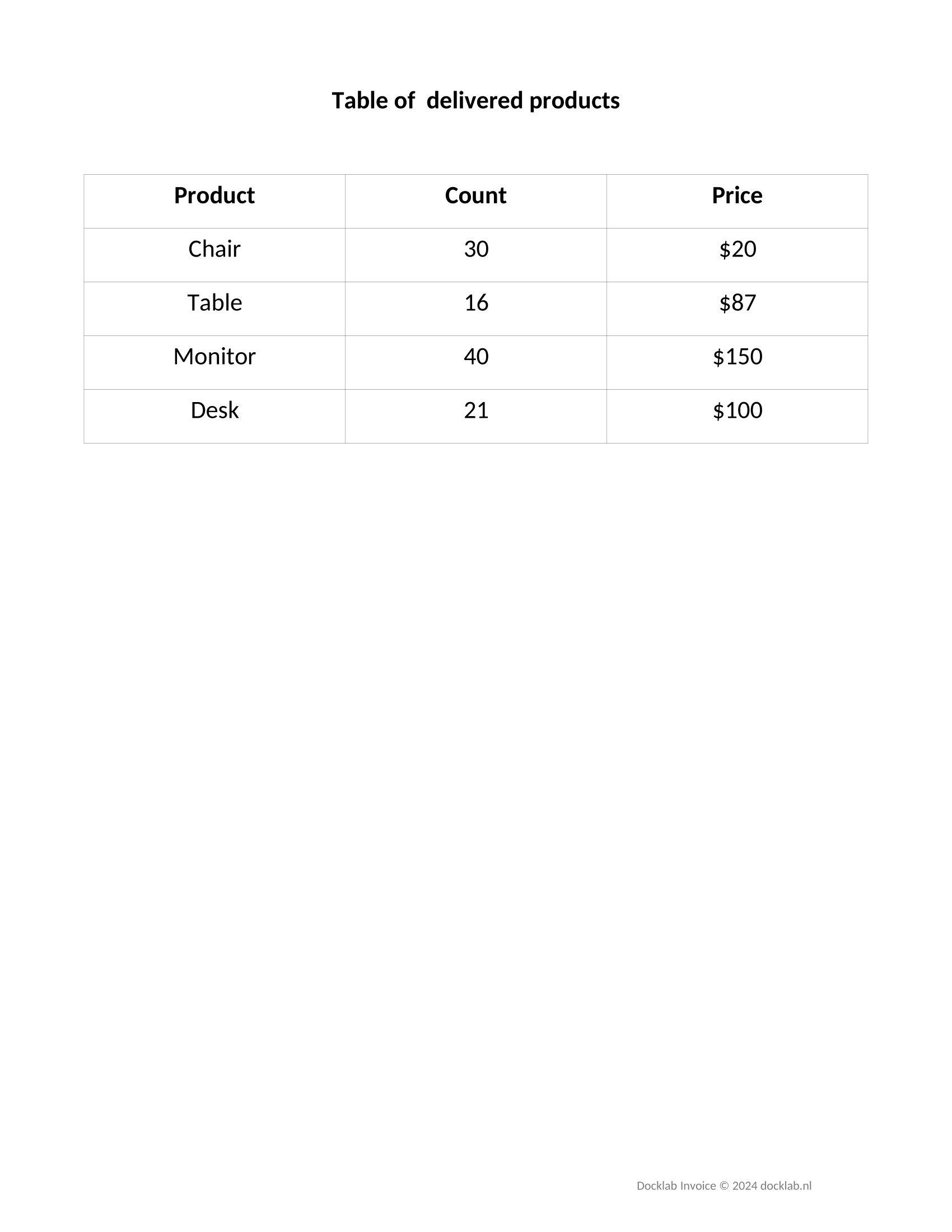
We will also modify the configuration so that we can extract the 2 tables:
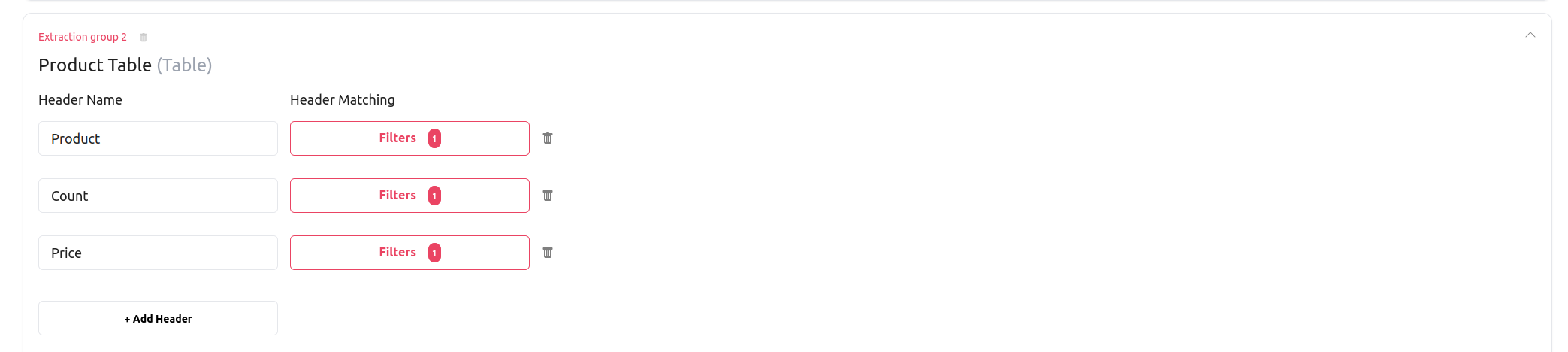
Finally, we will append a couple of Table referencers to our schema, to illustrate the behaviour of the various arguments:
-
{ "Invoice Data": { "Name of contact person": "@FieldValue[Data.Name]", "Phone number": "@FieldValue[Data.Phone]", "Contact email address": "@FieldValue[Data.Email]" }, "Invoice Data Joined": "$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')", "All numerical values in Invoice": "@FieldValueList[Data.'Numerical values']", "Indexing": { "by entries": "@FieldValueList[Data.'Numerical values'][0, 3, 5, 7]", "by range": "@FieldValueList[Data.'Numerical values'][1:4]" }, "Tables": { "All tables": "@Table['Product Table']", "First table": "@Table['Product Table'][0]", "Second table": "@Table['Product Table'][1]", "First table product and price": "@Table['Product Table'][0][Product, Price]", "Second table count": "@Table['Product Table'][1]['Count']", "All tables header and first row": "@Table['Product Table'][][][0, 1]", "All tables first row first column": "@Table['Product Table'][0, 1][Product][1]", "Second table first 2 counts": "@Table['Product Table'][1][Count][1:3]" } } -
<Invoice_Data> <Name_of_contact_person>@FieldValue[Data.Name]</Name_of_contact_person> <Phone_number>@FieldValue[Data.Phone]</Phone_number> <Contact_email_address>@FieldValue[Data.Email]</Contact_email_address> </Invoice_Data> <Invoice_Data_Joined>$join(@FieldValue[Data.Name], @FieldValue[Data.Email], @FieldValue[Data.Phone], '|')</Invoice_Data_Joined> <All_numerical_values_in_Invoice> <Numbers>@FieldValueList[Data.'Numerical values']</Numbers> </All_numerical_values_in_Invoice> <Indexing> <by_entries>@FieldValueList[Data.'Numerical values'][0, 3, 5, 7]</by_entries> <by_range>@FieldValueList[Data.'Numerical values'][1:4]</by_range> </Indexing> <Tables> <All_tables>@Table['Product Table']</All_tables> <First_table>@Table['Product Table'][0]</First_table> <Second_table>@Table['Product Table'][1]</Second_table> <First_table_product_and_price>@Table['Product Table'][0][Product, Price]</First_table_product_and_price> <Second_table_count>@Table['Product Table'][1]['Count']</Second_table_count> <All_tables_header_and_first_row>@Table['Product Table'][][][0, 1]</All_tables_header_and_first_row> <All_tables_first_row_first_column>@Table['Product Table'][0, 1][Product][1]</All_tables_first_row_first_column> <Second_table_first_2_counts>@Table['Product Table'][1][Count][1:3]</Second_table_first_2_counts> </Tables>
Performing an extraction with the provided schema will yield the following results
-
{ "Invoice Data":{"Name of contact person":"Emma","Phone number":"(123) 451-7897","Contact email address":"emma@fieldlab.nl"}, "Invoice Data Joined":"Emma|emma@fieldlab.nl|(123) 451-7897", "All numerical values in Invoice":["431","326","16", ...], "Indexing":{"by entries":["431","2","215","851"],"by range":["326","16","2"]}, "Tables":{ "All tables":[ [["Product","Count","Price"],["Keyboard","11","$21"],["Mouse","17","$100"],["Screen","10","$30"],["Table","13","$25"],["Notebooks","54","$5"]], [["Product","Count","Price"],["Chair","30","$20"],["Table","16","$87"],["Monitor","40","$150"],["Desk","21","$100"]]], "First table":[[["Product","Count","Price"],["Keyboard","11","$21"],["Mouse","17","$100"],["Screen","10","$30"],["Table","13","$25"],["Notebooks","54","$5"]]], "Second table":[[["Product","Count","Price"],["Chair","30","$20"],["Table","16","$87"],["Monitor","40","$150"],["Desk","21","$100"]]], "First table product and price":[[["Product","Price"],["Keyboard","$21"],["Mouse","$100"],["Screen","$30"],["Table","$25"],["Notebooks","$5"]]], "Second table count":[[["Count"],["30"],["16"],["40"],["21"]]], "All tables header and first row":[ [["Product","Count","Price"],["Keyboard","11","$21"]], [["Product","Count","Price"],["Chair","30","$20"]]], "All tables first row first column":[ [["Keyboard"]], [["Chair"]]], "Second table first 2 counts":[[["30"],["16"]]] } } -
<Invoice_Data> <Contact_email_address>emma@fieldlab.nl</Contact_email_address> <Name_of_contact_person>Emma</Name_of_contact_person> <Phone_number>(123) 451-7897</Phone_number> </Invoice_Data> <Invoice_Data_Joined>Emma|emma@fieldlab.nl|(123) 451-7897</Invoice_Data_Joined> <All_numerical_values_in_Invoice> <Numbers>431</Numbers> <Numbers>326</Numbers> <Numbers>16</Numbers> <Numbers>2</Numbers> <Numbers>2023</Numbers> <Numbers>215</Numbers> <Numbers>321</Numbers> <Numbers>851</Numbers> <Numbers>521</Numbers> <Numbers>200</Numbers> <Numbers>00</Numbers> <Numbers>375</Numbers> <Numbers>00</Numbers> <Numbers>50</Numbers> <Numbers>00</Numbers> <Numbers>4</Numbers> <Numbers>25</Numbers> <Numbers>26</Numbers> <Numbers>56</Numbers> <Numbers>551</Numbers> <Numbers>56</Numbers> <Numbers>11</Numbers> <Numbers>21</Numbers> <Numbers>17</Numbers> <Numbers>100</Numbers> <Numbers>10</Numbers> <Numbers>30</Numbers> <Numbers>13</Numbers> <Numbers>25</Numbers> <Numbers>54</Numbers> <Numbers>5</Numbers> </All_numerical_values_in_Invoice> <Indexing> <by_entries>431</by_entries> <by_entries>2</by_entries> <by_entries>123</by_entries> <by_entries>7892</by_entries> <by_range>326</by_range> <by_range>16</by_range> <by_range>2</by_range> </Indexing> <Tables> <All_tables>Product</All_tables> <All_tables>Count</All_tables> <All_tables>Price</All_tables> <All_tables>Keyboard</All_tables> <All_tables>11</All_tables> <All_tables>$21</All_tables> <All_tables>Mouse</All_tables> <All_tables>17</All_tables> <All_tables>$100</All_tables> <All_tables>Screen</All_tables> <All_tables>10</All_tables> <All_tables>$30</All_tables> <All_tables>Table</All_tables> <All_tables>13</All_tables> <All_tables>$25</All_tables> <All_tables>Notebooks</All_tables> <All_tables>54</All_tables> <All_tables>$5</All_tables> <All_tables>Product</All_tables> <All_tables>Count</All_tables> <All_tables>Price</All_tables> <All_tables>Chair</All_tables> <All_tables>30</All_tables> <All_tables>$20</All_tables> <All_tables>Table</All_tables> <All_tables>16</All_tables> <All_tables>$87</All_tables> <All_tables>Monitor</All_tables> <All_tables>40</All_tables> <All_tables>$150</All_tables> <All_tables>Desk</All_tables> <All_tables>21</All_tables> <All_tables>$100</All_tables> <First_table>Product</First_table> <First_table>Count</First_table> <First_table>Price</First_table> <First_table>Keyboard</First_table> <First_table>11</First_table> <First_table>$21</First_table> <First_table>Mouse</First_table> <First_table>17</First_table> <First_table>$100</First_table> <First_table>Screen</First_table> <First_table>10</First_table> <First_table>$30</First_table> <First_table>Table</First_table> <First_table>13</First_table> <First_table>$25</First_table> <First_table>Notebooks</First_table> <First_table>54</First_table> <First_table>$5</First_table> <Second_table>Product</Second_table> <Second_table>Count</Second_table> <Second_table>Price</Second_table> <Second_table>Chair</Second_table> <Second_table>30</Second_table> <Second_table>$20</Second_table> <Second_table>Table</Second_table> <Second_table>16</Second_table> <Second_table>$87</Second_table> <Second_table>Monitor</Second_table> <Second_table>40</Second_table> <Second_table>$150</Second_table> <Second_table>Desk</Second_table> <Second_table>21</Second_table> <Second_table>$100</Second_table> <First_table_product_and_price>Product</First_table_product_and_price> <First_table_product_and_price>Price</First_table_product_and_price> <First_table_product_and_price>Keyboard</First_table_product_and_price> <First_table_product_and_price>$21</First_table_product_and_price> <First_table_product_and_price>Mouse</First_table_product_and_price> <First_table_product_and_price>$100</First_table_product_and_price> <First_table_product_and_price>Screen</First_table_product_and_price> <First_table_product_and_price>$30</First_table_product_and_price> <First_table_product_and_price>Table</First_table_product_and_price> <First_table_product_and_price>$25</First_table_product_and_price> <First_table_product_and_price>Notebooks</First_table_product_and_price> <First_table_product_and_price>$5</First_table_product_and_price> <Second_table_count>Count</Second_table_count> <Second_table_count>30</Second_table_count> <Second_table_count>16</Second_table_count> <Second_table_count>40</Second_table_count> <Second_table_count>21</Second_table_count> <All_tables_header_and_first_row>Product</All_tables_header_and_first_row> <All_tables_header_and_first_row>Count</All_tables_header_and_first_row> <All_tables_header_and_first_row>Price</All_tables_header_and_first_row> <All_tables_header_and_first_row>Keyboard</All_tables_header_and_first_row> <All_tables_header_and_first_row>11</All_tables_header_and_first_row> <All_tables_header_and_first_row>$21</All_tables_header_and_first_row> <All_tables_header_and_first_row>Product</All_tables_header_and_first_row> <All_tables_header_and_first_row>Count</All_tables_header_and_first_row> <All_tables_header_and_first_row>Price</All_tables_header_and_first_row> <All_tables_header_and_first_row>Chair</All_tables_header_and_first_row> <All_tables_header_and_first_row>30</All_tables_header_and_first_row> <All_tables_header_and_first_row>$20</All_tables_header_and_first_row> <All_tables_first_row_first_column>Keyboard</All_tables_first_row_first_column> <All_tables_first_row_first_column>Chair</All_tables_first_row_first_column> <Second_table_first_2_counts>30</Second_table_first_2_counts> <Second_table_first_2_counts>16</Second_table_first_2_counts> </Tables>
@Checkbox[<Group name>.<Field name>]
The checkbox referencer works in a similar way to the field value referencer. It is used to reference checkboxes that expect a single extracted value or list of extracted values (i.e. List Extraction or Labeled Group Extraction). Checkbox referencers take a single argument, of the form <Group name>.<Field name>, specifying the group name and field name of the value being referenced.
Let’s have a look at an example. We will augment the extraction configuration below to extract all types of checkboxes found in the document:

We will now create our schema to reference the extracted list of checkbox:
-
{ "Classification": "@Checkbox[Checkbox.'Checkbox Classification']", "List Extraction": "@Checkbox[Checkbox.'Checkbox List Extraction']", "Labeled Group Extraction": "@Checkbox[Checkbox.'Checkbox Labeled Group Extraction']" } -
<Classification> <Classification_Checkbox>@Checkbox[Checkbox.'Checkbox Classification']</Classification_Checkbox> </Classification> <List_Extraction> <List_Extraction_Checkbox>@Checkbox[Checkbox.'Checkbox List Extraction']</List_Extraction_Checkbox> </List_Extraction> <Labeled_Group_Extraction> <Labeled_Group_Extraction_Checkbox>@Checkbox[Checkbox.'Checkbox Labeled Group Extraction']</Labeled_Group_Extraction_Checkbox> </Labeled_Group_Extraction>
Let’s have a look at the output:
-
{ "Classification": [["checked",""]], "List Extraction": [["checked",""],["unchecked",""],["checked",""]], "Labeled Group Extraction": [[ "checked", "Line Item selected" ], [ "unchecked", "Line item unselected" ], [ "checked", "Line item selected" ]] } -
<Classification> <Classification_Checkbox>checked</Classification_Checkbox> <Classification_Checkbox></Classification_Checkbox> </Classification> <List_Extraction> <List_Extraction_Checkbox>checked</List_Extraction_Checkbox> <List_Extraction_Checkbox></List_Extraction_Checkbox> </List_Extraction> <List_Extraction> <List_Extraction_Checkbox>unchecked</List_Extraction_Checkbox> <List_Extraction_Checkbox></List_Extraction_Checkbox> </List_Extraction> <List_Extraction> <List_Extraction_Checkbox>checked</List_Extraction_Checkbox> <List_Extraction_Checkbox></List_Extraction_Checkbox> </List_Extraction> <Labeled_Group_Extraction> <Labeled_Group_Extraction_Checkbox>checked</Labeled_Group_Extraction_Checkbox> <Labeled_Group_Extraction_Checkbox>Line Item selected</Labeled_Group_Extraction_Checkbox> <Labeled_Group_Extraction_Checkbox>unchecked</Labeled_Group_Extraction_Checkbox> <Labeled_Group_Extraction_Checkbox>Line item unselected</Labeled_Group_Extraction_Checkbox> <Labeled_Group_Extraction_Checkbox>checked</Labeled_Group_Extraction_Checkbox> <Labeled_Group_Extraction_Checkbox>Line item selected</Labeled_Group_Extraction_Checkbox> </Labeled_Group_Extraction>
@Fixed[<Fixed Value>]
As the name suggests, the Fixed referencer is used to reference a constant, predefined value. Unlike the other referencers, it does not extract data from a document, but instead, it injects a fixed value directly into the field. This can be useful when a specific, unchanging value needs to be populated in the schema.
-
{ "Fixed Value": "@Fixed['Docheart']" } -
<Fixed_Value>@Fixed['Docheart']</Fixed_Value>
Let’s have a look at the output:
-
{ "Fixed Value": "Docheart" } -
<Fixed_Value>Docheart</Fixed_Value>
Operators
As mentioned above, on top of referencers, OSDL also supports operators, which act as functions that can be applied to one of more referencers to perform simple computations on the extracted data. OSDL supports a wide range of operator, which are listed below:
- $merge(@Referencer_1, @Referencer_2, …, @Referencer_k) - merges mulitple lists into one list (without removing duplicates). Single values will be treated as one element lists.
- $union(@Referencer_1, @Referencer_2, …, @Referencer_k) - merges multiple lists into one list, removing the duplicates. If only one list is provided, the union operator will simply remove all duplicates (like the $set operator). Non-list values will be treated as one element lists by this operator. Lists of lists (such as tables) will be implictly flattened.
- $intersect(@Referencer_1, @Referencer_2, …, @Referencer_k) - returns the set (list without duplicates) of values that appears in all provided argument lists. Non-list values will be treated as one element lists by this operator. Lists of lists (such as tables) will be implictly flattened.
- $set(@Referencer) - removes all duplicates from a list. Lists of lists (such as tables) will be implictly flattened.
- $list(@Referencer) - turns a field value into a single element list. Lists will be returned as they are (no modifications will be performed on the list elements)
- $flatten(@Referencer) - flattens an arbitrarily deep list of lists into one list. Non-list values will be treated as one element lists by this operator.
- $sort(@Referencer, type) - returns the same list sorted in increasing order. Non-list values will be treated as one element lists by this operator. Lists of lists will be treated as flattened lists. The type argument specifies whether or not the order should be alphanumerical ($sort(@Referencer, alnum)) or numerical ($sort(@Referencer, num)). In numerical sorting, non-number will always be added at the end of the list. The default behaviour is alphanumerical sorting.
- $rsort(@Referencer, type) - same as $sort(@Referencer, type), but in decreasing order
- $reverse(@Referencer) - reverses the order of a list. Non-list values will be treated as one element lists by this operator.
- $join(@Referencer_1, @Referencer_2, …, @Referencer_k, sep) - join multiple values into one string. The arguments can be one list, multiple lists or single field values. Lists of lists will be treated as flattened lists. The last argument is the separator and it defines the character sequence to be used as separator between the joined values.
- $concat(@Referencer_1, @Referencer_2, …, @Referencer_k) - equivalent to $join(@Referencer_1, @Referencer_2, …, @Referencer_k, ‘’)
- $index(@Referencer, index) - indexes into a list. Non-list values will be treated as one element lists by this operator. Indices that are out of bound will be ignored. The index can be one value, e.g. $index(@Referencer, 0), a list of values, e.g. $index(@Referencer, 0, 4, 7) or a range $index(@Referencer, 2:7)
- $mapTo(@Referencer, dict) - maps each value from a list (or single value) based on a given dictionary. If a value in the list does not have a corresponding key in the dictionary, the value remains unchanged. Non-list values will be treated as single-element lists.
- $zip(@Referencer_1, @Referencer_2, …, operator) - combines multiple lists into one list of tuples, where each tuple contains elements from the same position in the input lists. You can apply an operator (like merge) to perform additional actions on the zipped values. Non-list values will be treated as single-element lists.
Combining operators for advanced data processing
The OSDL operators are a very poweful tool, since they can be combined to define highly complex behaviour. For instance, we want to output the 2 largest unique product counts from the 2 tables joined together by *, combined in one list with the smallest count, we can define the following expression.
-
{ "Biggest 2 unique counts and smallest count": "$merge($join($index($rsort($union(@Table['Product Table'][0][Count], @Table['Product Table'][1][Count]), num), 0, 1), ' * '), $index($sort(@Table['Product Table'][][Count]), 0))", "MappedValue": "$mapTo($rsort($set(@FieldValueList[Data.'Numerical values']), num), '{\"375.00\": \"375$$\"}')", "zippedValue": "$zip(@FieldValueList[Data.'Numerical values'],$mapTo(@FieldValueList[Data.'Numerical values'], '{\"375.00\": \"375$$\", \"200.00\": \"200$$\", \"50.00\": \"50$$\", \"26.56\": \"26$$\"}'), 'merge')" } -
<Schema> <Biggest_2_unique_counts_and_smallest_count> <Number>$merge($join($index($rsort($union(@Table['Product Table'][0][Count], @Table['Product Table'][1][Count]), num), 0, 1), ' * '), $index($sort(@Table['Product Table'][][Count]), 0))</Number> </Biggest_2_unique_counts_and_smallest_count> <Map> <MappedValue>$mapTo($rsort($set(@FieldValueList['Invoice Information'.'Amounts']), num), '{"375.00": "375$$"}')</MappedValue> </Map> <Zip> <zipTest>$zip(@FieldValueList['Invoice Information'.'Amounts'],$mapTo(@FieldValueList['Invoice Information'.'Amounts'], '{"375.00": "375$$", "200.00": "200$$", "50.00": "50$$", "26.56": "26$$"}'), 'merge')</zipTest> </Zip> </Schema>
Performing an extraction with this schema yields the following result:
-
{ "Biggest 2 unique counts and smallest count": [ "54 * 40", "10" ], "MappedValue": ["375$$", "200.00", "50.00", "26.56"], "zippedValue": [ ["200.00", "200$$"], ["375.00", "375$$"], ["50.00", "50$$"], ["26.56", "26$$"], ] } -
<Schema> <Biggest_2_unique_counts_and_smallest_count> <Number>40 * 30</Number> <Number>16</Number> </Biggest_2_unique_counts_and_smallest_count> <Map> <MappedValue>375$$</MappedValue> <MappedValue>200.00</MappedValue> <MappedValue>26.56</MappedValue> </Map> <Zip> <zipTest>['200.00', '200$$']</zipTest> <zipTest>['375.00', '375$$']</zipTest> <zipTest>['26.56', '26$$']</zipTest> </Zip> </Schema>